PC版のページに相互RSSというブログパーツを入れてから、RSSについていろいろ調べたことのまとめ。
すごく…長いです…
コンテンツを公開したタイミングで、その「更新情報」をサーバー上のXMLファイルなどに書き込む形式。
このフォーマットで書かれた情報をRSSフィードという。
RSSにはver.1系とver.2系があり、書式は2の方がシンプルで、比較的読み易い。
弊ブログのRSSを、Ver2.0で書いてみると
RSSを発行していないページの更新情報は、一般的なRSSリーダーでの取得が不可能。
RSSフィードはあくまでも各ページがあらかじめ用意しているものです。
だから、RSS未発行のページでは、フィードを取得できません。
例えばこのページには
ただ、各ブログサービスでは
 RSS未発行 フィードなどでぐぐると、結構いろんなサービスが出てきます。
RSS未発行 フィードなどでぐぐると、結構いろんなサービスが出てきます。
仕組みとしては、それぞれのサービスのサーバーにフィード用のファイルが作られるので、そのサービスが終了するとフィードを取得できなくなる感じでしょうか。
専門知識(と自前のサーバー)がある人は自分で組めたりするようですが、私などにはチンプンカンプンなので…
ここでは、これはいい!と思ったサイト様を紹介します。
素材は
トップページ(日記)に追記という形で更新されていくので、「記事ごとのフィード」が存在せず、このページのファイル更新日時を取得するか、記事を解析して立先生が記入された更新日を参照するしかありません。
またメタ情報が少なく、レイアウトも最小限のタグで組まれているので、逆に解析が難しいという。
Step 3 の終了後、RSSアイコンの横にランダムな数字で名づけられたXMLファイルへのリンクが出現するので、これをクリックします。すると…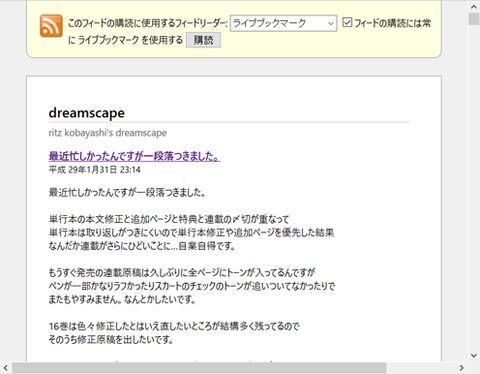 なんかいい感じにできてます!
なんかいい感じにできてます!
…ん? と、全記事の更新日がすべてフィードの作成日時になっているではありませんか!
と、全記事の更新日がすべてフィードの作成日時になっているではありませんか!
…思えば Step 3.で記事の更新日=
「日附っぽいマクロ」を自動的にアイテムの更新日として認識してくれるのかな?ぐらいに思っていましたが、まあそうはなりませんでした。
ダメだったか…
このブログの相互RSSに「咲-Saki-情報」という文字が見えると思いますが、これはサイト名ではなく、Google Alert がWEB上で取得した咲-Saki-関連の新着記事のフィード(のラベル)です。
ハイパーリンクの
謎なのは、「咲-Saki-」というキーワードを指定しているだけなので、別途登録している咲-Saki-関連のブログの新着記事などが取得されてもおかしくないのに、今のところ重複がないということです。
すごく…長いです…
目次
RSSとは
Rich Site Summary の略。コンテンツを公開したタイミングで、その「更新情報」をサーバー上のXMLファイルなどに書き込む形式。
このフォーマットで書かれた情報をRSSフィードという。
RSSにはver.1系とver.2系があり、書式は2の方がシンプルで、比較的読み易い。
弊ブログのRSSを、Ver2.0で書いてみると
<?xml version="1.0" encoding="UTF-8"?> <rss version="2.0" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:sy="http://purl.org/rss/1.0/modules/syndication/" xmlns:admin="http://webns.net/mvcb/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">この辺は決まり文句。
<channel>
<rss>タグの直下には<channel>タグを置き、その中にページの更新情報を書く。
ブログ名
<title>一萬人の麓路()</title>
RSSのURL
<link>http://humotomiti.blog.jp/index.rdf</link>
サイトの説明
<description>咲-Saki-のブログです。</description>
サイトの言語
<dc:language>ja</dc:language>
サイト管理人の名前
この場合、私のライブドアブログID
<dc:creator>nsforscoyan</dc:creator>
RSSの最終更新日時
<dc:date>2017-01-31T00:00:00+09:00</dc:date>
日時の書式はいろいろありますが、推奨されているのはこのW3CDTFフォーマット。
記事の更新情報
<item>
<item>タグは、最新記事の情報で、複数記載可。
一般的には最大15本分ぐらいまで。<item>タグの中身<title>記事タイトル</title> <link>記事URL</link> <description>記事の内容</description> <dc:subject>記事のカテゴリ</dc:subject> <dc:creator>記事を書いた人</dc:creator> <dc:date>記事の作成日時</dc:date> </item> </channel> </rss>
RSSを発行していないページの更新情報は、一般的なRSSリーダーでの取得が不可能。
ブログサービスごとのRSS
相互RSSの管理画面で、更新情報を取得したいサイトのURLを入力すると出てくるフィードは、そのサイトのメタタグに書いてあるアドレスを持ってきているだけで、その場でフィード自体を生成しているわけではありません。RSSフィードはあくまでも各ページがあらかじめ用意しているものです。
だから、RSS未発行のページでは、フィードを取得できません。
例えばこのページには
<link rel="alternate" type="application/rss+xml" title="RSS" href="http://humotomiti.blog.jp/index.rdf" />という
<meta>タグがあり、ここのhref属性「http://humotomiti.blog.jp/index.rdf」がRSSフィードのアドレスになります。ただ、各ブログサービスでは
<meta>タグに書いていないRSSを発行している場合があり、その情報はリーダーが自動的に検知してくれるわけでもないので、自分で調べる必要があります。
ライブドアブログ
トップページ
http://humotomiti.blog.jp/
http://humotomiti.blog.jp/index.rdfトップページのURLに「index.rdf」がつくだけ。カテゴリ別ページ
例として、咲-Saki-カテゴリ(この場合カテゴリID:910779)http://humotomiti.blog.jp/archives/cat_910779.htmlhttp://humotomiti.blog.jp/archives/cat_910779.xmlURLの「.html」を「.xml」に変えるだけFC2ブログ
トップページ
http://negative4sugar.blog.fc2.com/
http://negative4sugar.blog.fc2.com/?xmlトップページのURLに「?xml」がつくだけ。カテゴリ別ページ
例として、咲-Saki-カテゴリ(この場合カテゴリ番号:1)http://negative4sugar.blog.fc2.com/blog-category-1.htmlhttp://negative4sugar.blog.fc2.com/?xml&category=1URLの「blog-category-1.html」を「?xml&category=1」に変えるだけユーザータグ別ページ
http://negative4sugar.blog.fc2.com/?tag=小鍛治健夜
http://negative4sugar.blog.fc2.com/?xml&utag=小鍛治健夜タグ名が「小鍛治健夜」のように日本語(全角文字)の場合は、実際には「%E5%B0%8F%E9%8D%9B%E6%B2%BB%E5%81%A5%E5%A4%9C」のようにパーセントエンコードします(アドレスバーのURLからコピペすると、自動的に変換されます)。Word Press
五十嵐あぐり先生のホームページを例にしますトップページ
http://anti-heroine.sakura.ne.jp/wp/
http://anti-heroine.sakura.ne.jp/wp/?feed=rssトップページのURL末尾に「?feed=rss」がつくだけ。その他のページ
トップページに「メタ情報>投稿のRSS/コメントのRSS」というリンクがあるんですが、ここのRSSは相互RSSに無効と判断されるので、使えません。
イラストページなんかのフィードが欲しいのでいろいろ調べたんですが、よくわかりませんでした。Blogger
トップページ
http://xxxxxxxx.blogspot.jp/http://xxxxxxxx.blogspot.com/feeds/posts/defaultURL末尾の「.jp/」を「.com/feeds/posts/default」に変える。ラベル
Blogger にはカテゴリという概念が無く、「ラベル」(タグに近い)で記事を分類しますが、個別のサイトが手動で設定している場合を除き、ラベル別のRSSは発行されていないようです。アメブロ
植田佳奈さまのブログを例にしますトップページ
http://ameblo.jp/uedakanablog/
http://rssblog.ameba.jp/uedakanablog/rss20.xml
「ameblo.jp」の前に「rssblog.」を挿入し、最後に「rss20.xml」をつけ加えます。テーマ別ページ
RSSが取得できません。はてなブログ
トップページ
http://xxxxxxxx.hatenablog.com/
http://xxxxxxxx.hatenablog.com/feedURL末尾に「feed」をつけ加えます。カテゴリ別ページ
カテゴリ名が「咲-Saki-」の場合http://xxxxxxxx.hatenablog.com/archive/category/咲-Saki-http://xxxxxxxx.hatenablog.com/feed/category/咲-Saki-URLの「/archive/」の部分を「/feed/」に変えます。
全角文字「咲」は、実際にはパーセントエンコーディングで「%E5%92%B2」とします。Yahoo!ブログ
トップページ
http://blogs.yahoo.co.jp/arasa-dayo/
http://blogs.yahoo.co.jp/arasa-dayo/rss.xml最後に「rss.xml」をつけ加えます。Seesaa BLOG
トップページ
http://naniiwaseruno.seesaa.net/
http://naniiwaseruno.seesaa.net/index.rdf最後に「index.rdf」をつけ加えます。
RSS未発行のページのフィード取得
フィードを取得できない(=RSSが発行されていない)ページもたくさんありますが、RSS未発行 フィードなどでぐぐると、結構いろんなサービスが出てきます。仕組みとしては、それぞれのサービスのサーバーにフィード用のファイルが作られるので、そのサービスが終了するとフィードを取得できなくなる感じでしょうか。
専門知識(と自前のサーバー)がある人は自分で組めたりするようですが、私などにはチンプンカンプンなので…
ここでは、これはいい!と思ったサイト様を紹介します。
素材は
http://www.sciasta.com/ritz/難関、立先生のHP。
トップページ(日記)に追記という形で更新されていくので、「記事ごとのフィード」が存在せず、このページのファイル更新日時を取得するか、記事を解析して立先生が記入された更新日を参照するしかありません。
またメタ情報が少なく、レイアウトも最小限のタグで組まれているので、逆に解析が難しいという。
Final Scraper
「あらゆるウェブページをRSSフィードに変換します」というキャッチコピーを恃んで、立先生のHPのフィードを取得しようとしましたが、失敗。
数分待ってフィード自体はできたんですが、ページの解析がうまくいかなかったらしく、プロフィールページ・バナー画像・お絵描きBBS のリンク部分を記事と解釈されてしまいました。<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom"> <channel> <atom:link href="https://www.happyou.info/fs/gen.php?u=1841581733&p=-425347360" rel="self" type="application/rss+xml"></atom:link> <lastBuildDate>Wed, 1 Feb 2017 01:14:15 +0000</lastBuildDate> <generator>happyou.info(patid:-1979244960, score:28090, lesser:false, pat:1100d01-00Ig0502avNMk3Zrgt0gPT0g)</generator> <title>dreamscape</title> <link>http://www.sciasta.com/ritz/</link> <description>This feed was generated by #happyou_info at Wed Feb 01 01:14:15 UTC 2017</description> <item> <title>profile</title> <link>http://www.sciasta.com/ritz/about.html</link> <description>(略)</description> <guid isPermaLink="true">http://www.sciasta.com/ritz/about.html</guid> </item> <!---- 略 ----> </channel> </rss>Page2Feed API
livedoor ラボ「EDGE」に公開されている実験的なサービス。
ちなみに、現在 Live Dwango Reader の BETA 機能としても使われています。
なんとブックマークレットも用意されており、目的のページに行ってワンクリックするだけでフィードが作れるという手軽さ。
ただ、あくまでも実験的なサービスということで、ある日突然終了というリスクもあります。
結果はと言うと、ここでも dreamscape の正常なフィードは生成されませんでした。
できたのは、立先生のプロフィールページだけが恒常的に指定されるフィードです…- 【5月21日追記】
このサービスは終了しました
livedoor ラボ「EDGE」 開発日誌 : 【追記 2017/05/16】Page2Feed APIサービス終了のお知らせ - livedoor Blog(ブログ)
FEED43
英語サイト、かつ自動生成ではなくHTMLの情報を手動で入力する必要がありますが、解説サイト様のおかげでなんとかチャレンジできました。Step 1. Specify source page address (URL)
アドレス指定。立先生のHPのURLを入力します。
エンコード指定は空欄でもOK。<meta>タグの文字コード指定をちゃんと読んでくれます。
を押すと、入力内容が確定すると同時に、入力したURLのHTMLソースが表示されます。Step 2. Define extraction rules
ページの解析パターンを入力します。Step 1.で表示されたHTMLが、パターンのソースとして使えます。- Global Search Pattern
- そのページのユニークな目印(ヘッダーとか)を入力する欄ですが、単に
{%}とだけ書けばいいそうです。この記号はマクロ変数として使います。- Item (repeatable) Search Pattern
- ページの中で繰り返されるパターンを入力します。
記事のマークアップパターンなど不変の部分はそのまま書き、題名や本文など、個別に違う部分を{%}で指定します。<hr><strong>16.12.27</strong><br><br> 最近忙しかったんですが一段落つきました。<br> <br> 単行本の本文修正と追加ページと特典と連載の〆切が重なって<br> 単行本は取り返しがつきにくいので単行本修正や追加ページを優先した結果<br> なんだか連載がさらにひどいことに…自業自得です。<br> <!--------------------以下略-------------------->
- 立先生の日記のパターンは、これ。 書き始めに
<hr>タグが入り、その直後の日附部分を<strong>タグで囲み、<br>タグ二つのあとに本文が続きます。
これをマクロ変数を使って書くと、<hr><strong>{%}</strong><br><br>{%}<br>{%}普通のブログなんかだと、記事のヘッダーやフッターのタグを目印にできると思うんですが、ここまでシンプルだと本文の中にたまたま同じパターンが出てきてしまうこともありそう。
ここでは{%}が三か所出ていますが、それぞれ{%1}、{%2}、{%3}として参照します。{%1}は日附、{%2}は「日附の後の本文第一行」。後者を記事タイトル代りにしようというわけです。{%}の数だけ数字を増やしていけば、すべてマクロとして使えます。
マクロにする必要がない部分は{*}とします。
以上を入力後にを押すと、特に問題が無ければ「OK」と表示され、上記パターンに合致した項目(日附と本文)がリスト形式で出力されます。
Step 3. Define output format
出力形式の定義に必要な項目は、以下の六つ。- Feed Title
- HPのタイトルをそのまま
dreamscape
- Feed Link
- HPへのリンクアドレス
http://www.sciasta.com/ritz/
- Feed Description
- 説明文
ritz kobayashi's dreamscape
- Item Title Template
- 記事タイトルの書式
{%2}- Item Link Template
- 記事へのリンク。
ただし行番号指定とかもできないので、トップページのURLをそのままhttp://www.sciasta.com/ritz/
- Item Content Template
- 記事本文の書式
{%2}<br>{%3}
以上を入力後にを押すと、特に問題が無ければ「OK」と表示され、上で指定した書式でフィードのプレビューが出力されます。
というわけで、dreamscape のソースは、上のパターン通り記事ごとにリスト化されました。
Step 4. Get your RSS feed
いよいよフィードの取得です。Step 3 の終了後、RSSアイコンの横にランダムな数字で名づけられたXMLファイルへのリンクが出現するので、これをクリックします。すると…
…ん?
…思えば Step 3.で記事の更新日=
{%1}、と定義したかったのに、それを記述する欄が無かったのですね。「日附っぽいマクロ」を自動的にアイテムの更新日として認識してくれるのかな?ぐらいに思っていましたが、まあそうはなりませんでした。
ダメだったか…
最終兵器 Google Alert
これは簡単・便利かつ強力。このブログの相互RSSに「咲-Saki-情報」という文字が見えると思いますが、これはサイト名ではなく、Google Alert がWEB上で取得した咲-Saki-関連の新着記事のフィード(のラベル)です。
ハイパーリンクの
url属性で元記事に転送されるようになっています。
使ってみる
設定は呆気ないほど簡単。
Google AlertにGoogleのアカウントでログインし、「アラートを作成…」(検索窓のようなテキストボックス)にキーワードを入力するだけで「マイアラート」が作成されます。
アラート名の横に出ているRSSアイコンのURLをリーダーに登録すると、入力したキーワードを含む新着情報が、随時配信されます。
一月に取得された記事はこちら。- 【OP差し替え】咲-saki- 【1期×全国編】(1/31 23:01)
- 実写映画『咲-Saki-』は原作ファンを納得させられるか? アニメ版との演出・キャスティング・構成の違いから ...(1/31 19:02)
- 『初恋サンライズ』×『咲-Saki-』(1/31 02:03)
- 【X21】大西亜玖璃 映画「咲-Saki-」公開記念学校別舞台挨拶に出演決定!!(1/30 15:14)
- タワレコ新宿始動のアイドル企画に清澄高校麻雀部が初登場! 衣裳展も期間限定開 (1/29 21:38)
- 【GTA5】北斗有情破顔拳 カー【咲-Saki】 (1/29 21:00)
- タコス大好き・優希が相思相愛コラボ!「咲-Saki-」×メキシカン・ファストフード「TACO BELL」コラボ ... (1/29 12:56)
まあ、Google検索上位のページから拾って来ているので、危ないサイトに飛ばされるような事はまず無いと思いますけれども。
実際にリンク先を確認しても、ニコニコ動画、芸能ニュースサイト、タレントさんの公式サイトなど、なるほどアクセスの多そうなページばかりでした。カスタマイズしてみる
ちょっと他のフィードとは性格が違うので、アイコンとCSS をカスタマイズしてみました。
相互RSSにずらっと並んでいるリンクから、Google Alert で取得した更新コンテンツだけを拾い出し、アイコンを変え、文字にCSSクラスを与えています。
目立たせる必要が無ければ要りませんが。追加する<script>タグ
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.12.4/jquery.min.js"></script> <script type="text/javascript"> $(function() { var _feed_item = '咲-Saki-情報', // 相互RSS管理画面で設定した Google Alert のフィード名 _blogroll_title = '咲-Saki-情報', // 相互RSSに表示する擬似サイト名 _icon_url = 'http://sample.com/image/icon.png', // 相互RSSに表示するアイコンのURL _cnt = 5, // 相互RSSに表示するコンテンツの数(1~5) _reg = new RegExp(_feed_item); $(".blogroll-link").each(function(){ var text = this.innerHTML; this.title = text, ( 0 == text.indexOf(_feed_item) ) && ( _cnt-- ) && ( this.innerHTML = text.replace(_reg, '<span class="saki-info">' + _blogroll_title + '</span>'), $(this).prev().attr("src", _icon_url) ); }); }); </script>このスクリプトは、相互RSSのリストから先頭の文字列が「咲-Saki-情報」になっているものを選んでいるだけなので、同じ名前、あるいは「咲-Saki-情報局」みたいに名前の前の方が一致しているサイト様を登録すると、そちらもピックアップしてしまう、ガバガバ仕様になっています。
その場合は、登録する前にこちらの設定を適当なものに変更すればいいだけですが。
この例では、管理画面での見易さを考慮してフィード名と擬似サイト名を同じにしています。
パフォーマンス的には前者は英数字の方がいいんでしょうけど。
あと、Google Alert で拾ったコンテンツだけでなく、全てのリンク先の記事タイトルがポップアップするようにしています(15行目)。追加する<style>タグ
「咲-Saki-情報」という文字のCSS。
<style type="text/css"> .saki-info{ color: #DC143C; font-weight: bold; } </style>
謎なのは、「咲-Saki-」というキーワードを指定しているだけなので、別途登録している咲-Saki-関連のブログの新着記事などが取得されてもおかしくないのに、今のところ重複がないということです。

コメント
コメント一覧 (3)
結構前に忍者ツールズのおまとめボタンというのに変えました。
グレーで統一されててカッコいいので。
すみません勘違いしてたみたいで。
「お気に入りアイコン」というのはこのブログのアイコンのことだったかも?と今更気がつきまして。
確かにこの頃、環境によって違うアイコンが表示されるのを、今のアイコンに統一してました。
古いバージョンでは牌の地色が完全な白だったのが、統一バージョンでは象牙色になっています。
ちょっとしたところに気づいて下さって嬉しいです!